
One area where AI has been posited to improve healthcare, although I hasten to add that this has yet to be proven, is diagnostic evaluation, the first and perhaps most consequential step in the “journey” from dis-ease to ease. A review by the Institute of Medicine of the National Academies of Sciences, Engineering and Medicine attributed a range of error rates depending upon the final arbiter, e.g., autopsy indicating a 20% error rate while using clinical outcomes, uncovered an average rate of about 11% but varied with the disease under consideration.
Diagnostic errors are also perpetuated downstream with inappropriate under- and over-testing and treatment, so giving physicians a bit of AI help seems like a good idea, especially because AI does as well or better on the standard medical examinations. But as I have quoted before, famed diagnostician Yogi Berra pointed out, “In theory, there is no difference between theory and practice. In practice, there is.” A new study reported in JAMA makes his point.
The study presented six clinical vignettes to 50 of what might be considered primary care residents and attending physicians (in family practice, internal and emergency medicine). The control group could use conventional, widely available materials to reach their diagnostic conclusions; while the treatment group could use an LLM, one of the large-language models, specifically ChatGPT. The vignettes were drawn from actual cases and included all the information available at the initial evaluation. Two outcomes were measured. The secondary outcome was the one most frequently employed – diagnostic accuracy. However, in this study, the primary outcome of interest was the underlying clinical reasoning. To get at participants’ diagnostic “reflections,” they were asked to identify and were graded [1] upon,
- their top 3 differential diagnoses
- case factors supporting or opposing each diagnosis
- their final diagnosis
- up to 3 next steps (e.g., tests) for further evaluation.
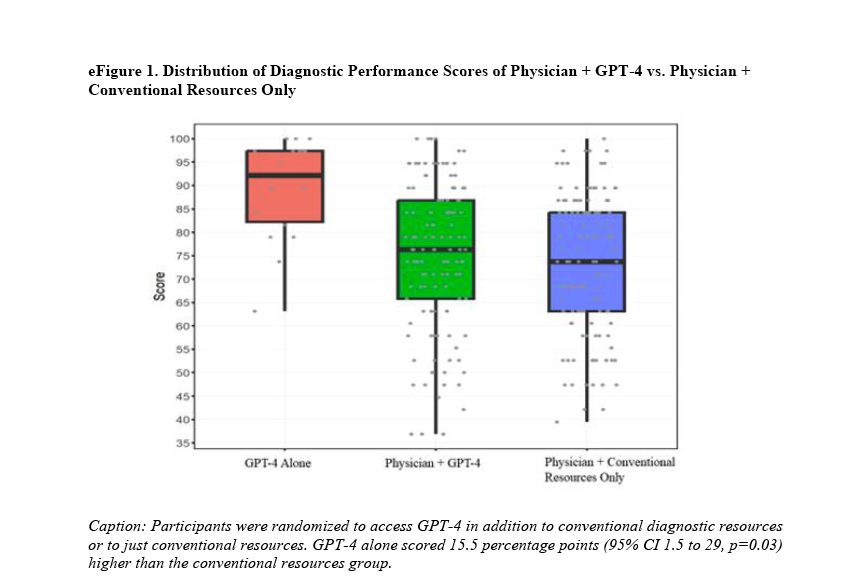 244 of the vignettes were completed between the two groups. The group utilizing AI completed their cases 15% more quickly, in roughly 8 and 2/3rd minutes. The AI group had a 1.4-fold greater odds of achieving the correct diagnosis. So far, so good for AI. However, all of these were secondary outcomes for the researchers; the real question for them was whether the use of AI improved clinical reasoning. In this instance, the AI median score was 76%, and the control's was 74% - no difference. That is visually presented in the positions of the green (AI-assisted) and blue (conventional resources) box and whisper plots. A careful examination of that graph demonstrates that AI, on its own, did much better than when used by human physicians as a tool.
244 of the vignettes were completed between the two groups. The group utilizing AI completed their cases 15% more quickly, in roughly 8 and 2/3rd minutes. The AI group had a 1.4-fold greater odds of achieving the correct diagnosis. So far, so good for AI. However, all of these were secondary outcomes for the researchers; the real question for them was whether the use of AI improved clinical reasoning. In this instance, the AI median score was 76%, and the control's was 74% - no difference. That is visually presented in the positions of the green (AI-assisted) and blue (conventional resources) box and whisper plots. A careful examination of that graph demonstrates that AI, on its own, did much better than when used by human physicians as a tool.
As an opinion piece in the New England Journal of Medicine points out, quietly referencing this study,
“New configurations of clinical decision-making partners, consisting of clinicians, AI agents, and patients (and their caregivers or proxies) may challenge many assumptions. For example, in a recent study, clinicians using AI assistance performed some tasks with less accuracy than they did without the AI tool.”
- Isaac Kohane, MD PhD Chair of the Department of Biomedical Informatics, Harvard Medical School
The researchers in this study offered an explanation for why AI did not have a significant effect, pointing out that none of the participants had specific training in the use of AI in diagnostic evaluation despite all of them using it. They pointed out that this was typically the case when AI was introduced to the workflow of hospital-based physicians. Given the sensitivity of AI’s chattering to human’s initial prompts, they suggested that physicians be trained how better “prompt” the chatbot. But wouldn’t it be more helpful, in both the short and long term, to work to improve the physician’s reasoning? In the end, physicians will have oversight. Isn’t clinical reasoning imperative when making judgments regarding the efforts of the AI tool? Is teaching how to prompt AI the best use of physician educational time?
As the researchers are quick to say,
“Results of this study should not be interpreted to indicate that LLMs should be used for diagnosis autonomously without physician oversight. … this does not capture competence in many other areas important to clinical reasoning, including patient interviewing and data collection.”
If humans are to maintain oversight, which is clearly the seeable future, would our scarce resources not be better spent on improving human interviewing and data collection skills? Dr. Kohane is correct when he writes,
“With any new clinical intervention, rigorous trials are the medical field’s best tools to drive the establishment of best practices.”
The headlong adoption of AI into healthcare is driven by administrators who measure only efficiency. After all, with the 1.5 minutes saved diagnostically using AI, another 1 or 2 patient transactions and revenue can be pushed into the primary care physician’s day. Deploying AI to serve as the public-facing interaction for calls, emails, and scheduling may achieve greater productivity, a code word for increased profitability. But, clinical care has a more significant downside when it goes awry, and we should not assume that AI will lift the clinical boat as much as the administrative one. Yuval Harari may have captured it best in describing what social roles and jobs will be AI’d away,
“Do they only want to solve a problem, or are they looking to establish a relationship with another conscious being?”
As AI steadily nudges its way into healthcare, it's tempting to think of it as a magic diagnostic wand. But diagnosis isn’t just about efficiency; it’s about understanding nuance and knowing which path to pursue—and that’s where real, human clinical reasoning shines. If we’re putting faith in AI to support physicians, maybe our focus should be on enhancing those human skills that can’t be prompted or coded. After all, healthcare’s ultimate purpose isn’t efficiency; it’s to heal people, not process them.
[1] Performance was graded with 1 point for each plausible diagnosis, and supporting/opposing findings were scored as 0 (incorrect), 1 (partially correct), or 2 (entirely correct). The final diagnosis earned 2 points if most accurate and 1 for plausible but less specific responses. Suggested next steps were also graded in the same manner.
Source: Large Language Model Influence on Diagnostic Reasoning JAMA Network Open DOI: 10.1001/jamanetworkopen.2024.40969
Compared with What? Measuring AI against the Health Care We Have NEJM 10.1056/NEJMp2404691

Chuck Dinerstein, MD, MBA
Director of Medicine
Dr. Charles Dinerstein, M.D., MBA, FACS is Director of Medicine at the American Council on Science and Health. He has over 25 years of experience as a vascular surgeon.


